Analyse technique pour la minimisation des ressources dans eMQTT5
eMQTT5 est un client MQTT v5.0 qui vise une faible utilisation des ressources pour les systèmes embarqués.
Afin d'atteindre cet objectif, nous avons utilisé de nombreuses astuces et techniques que nous présentons ci-dessous.
Pas d'allocation de tas
Sur un ordinateur de 4 Go, l'allocation de mémoire est très facile et peut se faire sans trop se soucier des conséquences. Sur un appareil de 64 ko, l'allocation est une chose qui, si elle n'est pas impossible, doit être très soigneusement réfléchie. L'allocation de la mémoire pose trois problèmes :
- L'espace limité et la gestion de l'épuisement de l'espace du tas
- Fragmentation
- Fuite de la mémoire
Le premier problème implique l'ajout de code pour gérer l'épuisement de l'espace de stockage, ce qui a un impact sur la taille binaire générée.
Le second problème survient lors de l'exécution des séquences habituelles "alloc A, alloc B, free A, alloc A, free B". Même si le logiciel est logiquement correct, il est très difficile pour un allocateur de récupérer la mémoire correctement dans ce cas, et cela finit par épuiser la mémoire, uniquement parce que l'allocateur ne peut pas fusionner l'espace libre correctement. Avoir un allocateur très intelligent prend aussi une taille binaire.
Le dernier problème est principalement dû à des bogues logiciels.
Afin d'éviter tous ces problèmes, eMQTT5 ne fait aucune allocation une fois créé. Il peut utiliser correctement les données allouées au tas, mais n'allouera rien sur le tas par lui-même.
Si des allocations sont absolument nécessaires, elles sont faites sur la pile et gérées en conséquence.
Pour allouer à partir de la pile (ce qui signifie que l'allocation sera libérée en quittant la fonction d'allocation), une classe appelée StackHeapBuffer est utilisée.
Elle permet de suivre si un tampon a été alloué par le tas ou la pile. Dans le premier cas, le tampon est free lorsque l'instance est détruite (RAII).
Habituellement, l'espace de la pile est limité, il n'est donc pas sûr d'allouer à partir de la pile sans faire très attention.
Le StackHeapBuffer est associé à la macro DeclareStackHeapBuffer qui vérifie si la pile ne va pas déborder de l'allocation et allouée sur le tas si elle pense qu'elle va déborder.
Vues
Dans un système embarqué, où les cycles de mémoire et de CPU sont limités, la copie des données est un gaspillage de ressources. Pour éviter cela, eMQTT5 utilise les vues et le modèle de visiteur pour permettre de visiter le buffer du réseau reçu et de mapper les vues sur le buffer sans aucune copie. MQTT est principalement un protocole de sérialisation. Cela signifie qu'il décrit comment les valeurs et les données doivent être disposées dans la mémoire. En inversant le protocole, il est possible d'extraire les valeurs et les données d'un paquet sérialisé sans jamais le copier.
Cela se fait dans la classe VisitorVariant. Cette classe contient un buffer qui a la taille exacte des plus grandes données de base qui peuvent être lues dans MQTT v5.0. Ce buffer est ensuite utilisé comme une variante, c'est-à-dire un objet de type variable. Selon le type de variante, le buffer sera compris comme un flottant, un entier variable, une vue de chaîne de caractères, etc...
La sécurité du type se fait à l'exécution, lorsque la classe de la variante est instanciée, le type de buffer attendu est enregistré et tout accès effectué sur un autre type retournera une valeur vide ou nulle. Cependant, pour éviter de créer des instances inutiles, une variante peut muter vers un autre type pour réutiliser un seul buffer.
La variante peut contenir des vues. Les vues sont des objets spécifiques contenant une taille et un pointeur. Vous pouvez accéder à une vue comme l'objet visualisé (même interface) mais aucune allocation/désallocation n'est faite avec une vue. Cela signifie qu'une vue n'est valide que tant que le buffer vers lequel elle pointe est valide. Vous ne pouvez pas stocker une vue pour l'utiliser plus tard.
template et héritage
Lees template impliquent généralement un gonflement du code généré et s'appuie sur le compilateur pour optimiser tous les éléments communs des nombreuses instanciations/spécialisations. Dans notre cas, il serait trop optimiste d'attendre du compilateur qu'il trouve le moyen d'optimiser toute la hiérarchie complète des messages MQTT et des types de variable.
Nous avons donc utilisé un schéma que nous avons appelé "héritage statique mixte".
En C++, l'héritage à partir d'une classe de base implique généralement l'ajout d'une table virtuelle à votre objet. Cette table virtuelle implique à la fois un coût sur la taille binaire générée (vous devez stocker de nombreuses fonctions dupliquées, comme les destructeurs virtuels), sur la mémoire d'exécution (tous vos objets ont une table de pointeurs qui leur est attachée) et des performances d'exécution (l'appel d'une méthode implique au moins 2 lookup en mémoire, une pour récupérer l'adresse de la méthode à appeler et ensuite appeler la méthode).
Notre héritage statique mixte se fait donc de cette manière :
- Le code commun de toutes les instanciations/spécialisations du modèle est déplacé vers une classe de base
- Ne jamais utiliser directement la classe de base (ce n'est pas un véritable héritage polymorphique ici)
- Pas de destructeur virtuel pour la classe de base (non requis car il n'est jamais appelé polymorphiquement)
- Marquer le template enfant
final(afin que le compilateur puisse optimiser la table virtuelle, puisqu'il peut calculer tous les appels de méthodes de manière statique)
Si l'usage exige un polymorphisme (par exemple, pour les "propriétés"), alors un destructeur virtuel est utilisé. Mais pour les autres classes, ne payez pas pour ce dont vous n'avez pas besoin.
Utilisation de la pile et récursivité
Le client utilise le concept de boucle d'évènements. L'utilisateur de la bibliothèque doit appeler la méthode eventLoop régulièrement pour que le client puisse gérer les cycles de réception des messages et de publications. Typiquement, lorsque la qualité de service (QoS) est utilisée, tout message transmis doit être acquiescé, voire enregistré et indexé.
Le problème fréquent des implémentations des clients arrivent lorsque les messages se croisent, par exemple, imaginons le cas suivant:
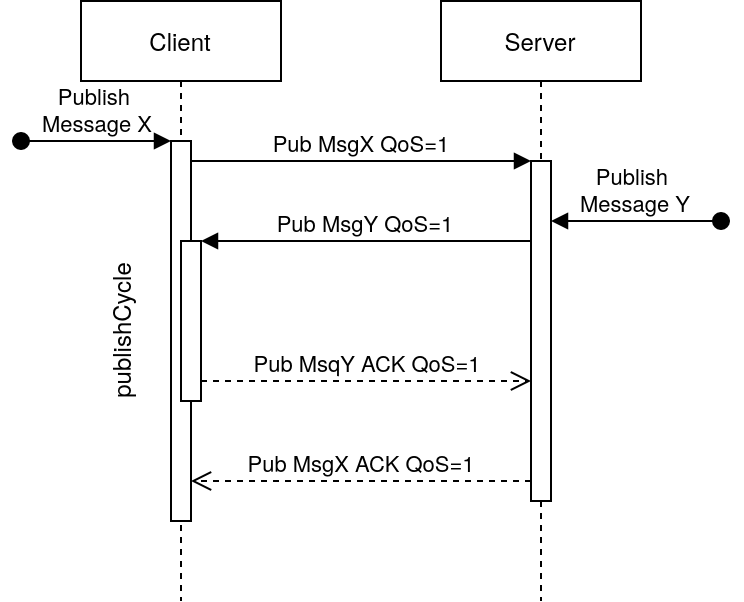
Le client souhaite publier un message X avec de la qualité de service (ici, un simple acquiescement). Après l'envoi du premier paquet, le broker veut publier lui aussi un message Y qui nécessite un acquiescement). Pour que cela fonctionne, il faudrait donc que le client qui a émis le premier paquet retourne dans sa boucle d'évènement, récupère le paquet du broker, le traite (c'est à dire lui envoi un acquiescement pour indiquer qu'il l'a bien reçu), puis attende que le broker lui envoie le paquet d'acquiescement de son propre message X.
Dans l'architecture du client eMQTT5, lorsque la boucle d'évènement est lancée, si un paquet est reçu, le cycle de publication (les acquiescement et/ou enregistrements) est lancé. Ce qui signifie que le client peut appeler MessageReceived::messageReceived qui peut à son tour vouloir publier un paquet.
Nous avons donc là un problème de récursivité qui pourrait amener à utiliser toute la pile puis planter la tâche CPU.
Sachant que la norme n'impose pas au broker de répondre immédiatement à un paquet de publication, il peut également attendre d'avoir reçu tous ses acquiescements avant d'envoyer les siens. Si il y a 20 paquets en cours d'envoi vers le client, cela veut dire 20 cycles de publications à faire avant de pouvoir terminer la première publication.
Le broker pourrait également réagir comme ceci:
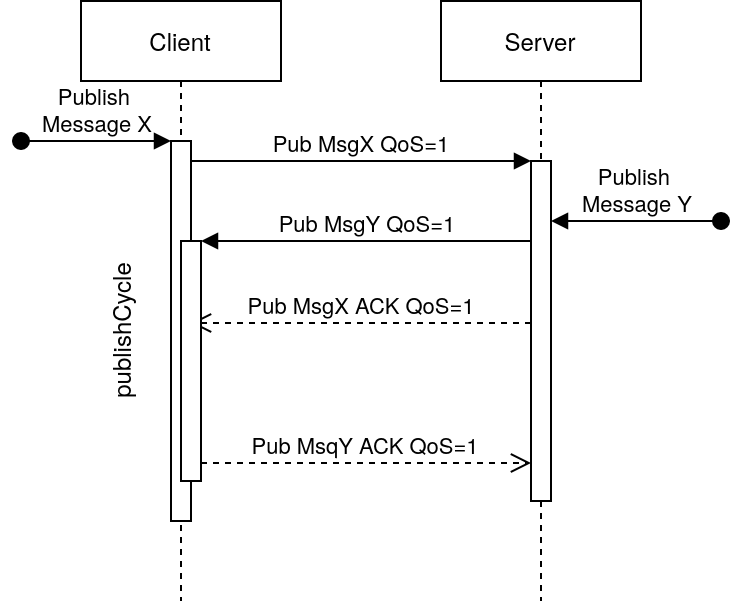
Ici la réponse est séquentielle, c'est à dire que le broker réagit immédiatement au paquet du client en envoyant un acquiescement dès qu'il a reçu le message X (mais après avoir envoyé le sien Y)
Le client eMQTT5 ne peut/veut pas avoir à stocker les messages en attente (car cela imposerait à allouer de la mémoire pour cela et donc de fragmenter le tas).
La solution choisie est donc d'observer uniquement le premier paquet reçu lors d'une publication (avec qualité de service). Si le paquet reçu de correspond pas à celui attendu (dans l'exemple ci-dessus, un acquiescement au message X), il retourne une erreur TranscientPacket.
C'est donc à l'utilisateur de retenter la publication ultérieurement dans ce cas.
L'utilisateur doit appeler eventLoop à nouveau pour traiter les messages en attente (afin de purger la file d'envoi du broker) puis retenter la publication juste après. Il n'est pas recommandé d'appeler eventLoop depuis la méthode messageReceived puisque cela crée une réentrance qui peut amener à un épuisement/débordement de la pile.
À noter que si l'utilisateur ne publie pas pendant une réception de message (dans la méthode messageReceived), alors le problème de réentrance ne se pose plus.
Pour résumer:
- Il faut toujours vérifier le retour de l'appel à la méthode
publish. - Si elle retourne
TranscientPacketalors il faut retenter la publication, après avoir appeléeventLoopafin de purger les messages en attente. - Si vous devez absolument publier un message lors de la réception d'un message (c'est à dire dans la méthode
messageReceived), alors il est recommandé d'utiliser un signal/une variable qui sera modifiée dans cette méthode, et vérifiée dans le code ayant appeléeventLooppour publication après la retour deeventLoop