Technical review for minimization of resources in eMQTT5
eMQTT5 is a MQTT v5.0 client that's targetting low resource usage for embedded system.
In order to achieve this goal, we've used many tricks and technics that we'll present below.
No heap allocation
On a 4GB computer, allocating memory is very easy and can be done without too much thinking about the consequences. On a 64kB device, allocation is something that, if not impossible, must be very carefully thought about. There are three issues with allocating memory:
- Limited space and handling of exhaustion of the heap space
- Fragmentation
- Leaking memory
The first issue implies adding code for handling exhaustion of the heap space, thus it has an impact on the generated binary size.
The second issue happens when doing usual "alloc A, alloc B, free A, alloc A, free B" sequences. Even if the software is logically correct, it's very difficult for an allocator to recover the memory correctly in that case, and it ends up with exhaustion of the memory, only because the allocator can not merge the free space correctly. Having a very smart allocator also takes binary size.
The last issue is mainly due to software bugs.
So in order to avoid all these issues, eMQTT5 does not do any allocation once created. It can use heap allocated data correctly, but will not allocate anything on the heap by itself.
If allocation are absolutely required, they are done on the stack and managed accordingly.
To allocate from the stack (meaning that the allocation will be freed upon leaving the allocating function), a class called StackHeapBuffer is used.
It's tracking whether a buffer was heap or stack allocated. In the former case, the buffer is free'd when the instance is destructed (RAII).
Usually stack space is limited, so it's not safe to allocate from the stack without taking great care. The StackHeapBuffer is paired with DeclareStackHeapBuffer macro that's checking if the stack will not overflow from the allocation and allocated on the heap if it thinks it'll overflow.
Views
In an embedded system, where memory and CPU cycles are limited, copying data around is a waste of resources. So to avoid this, eMQTT5 makes use of views and visitor pattern to allow visiting the received network buffer and map views on the buffer without any copy. MQTT is mainly a serialization protocol. This means that it describes how the values and data should be laid out in memory. By reversing the protocol, it's possible to extract values and data from a serialized packet without ever copying it.
This is done in the VisitorVariant class. This class contains a buffer that's the exact size of the largest basic data that can be read in MQTT v5.0. This buffer is then used as a variant, i.e. a variable type object. Depending on the variant type, the buffer will be understood as a float, a variable integer, a string view, etc...
The type safety is done at runtime, when the variant class is instantiated, the expected buffer type is saved and any access done without this type will return an empty/null value. Yet, to avoid creating useless instances, a variant can mutate to another type to reuse a single buffer.
The variant can hold views. Views are specific objects containing a size and a pointer. You can access a view like the viewed object (same interface) but no allocation/deallocation is either done with a view. This means that a view is only valid while the buffer it points to is valid. You can't store a view to use later on.
Template and inheritance
Template code usually implies code bloat and rely on the compiler to optimize all the common stuff from the many instantiations/specializations. In our case, expecting the compiler to figure out how to optimize all the complete hierarchy of MQTT message and variable type would be too optimistic.
So, we have used a pattern we called "mixed static inheritance".
In C++, inheriting from a base class usually implies adding a virtual table to your object. This virtual table implies both a cost of binary size (you must store many duplicated functions, like virtual destructors), runtime memory size (all your objects have a table of pointers attached to them) and runtime performance (calling a method implies at least 2 memory lookup, one for fetching the address of the method to call and then calling the method).
So our mixed static inheritance is done this way:
- Common code from all template instantiations/specialization is moved to a base class
- Never use the base class directly (it's not a true polymorphic inheritance here)
- Don't implement a virtual destructor for the base class (not required since it's never called polymorphically)
- Mark the template child final (so the compiler can optimize away the virtual table, since it can compute all method call statically)
If the usage requires polymorphism (for example, for Properties), then a virtual destructor is used. But for the other classes, don't pay for what you don't need.
Stack usage and recursion
The client uses the concept of an event loop. The library's user must call the eventLoop method regularly so that the client can manage message reception and publication cycles. Typically, when Quality of Service (QoS) is used, every message transmitted must be acknowledged, or even recorded and indexed.
A frequent problem in client implementations occurs when messages cross each other, for example, imagine the following case:
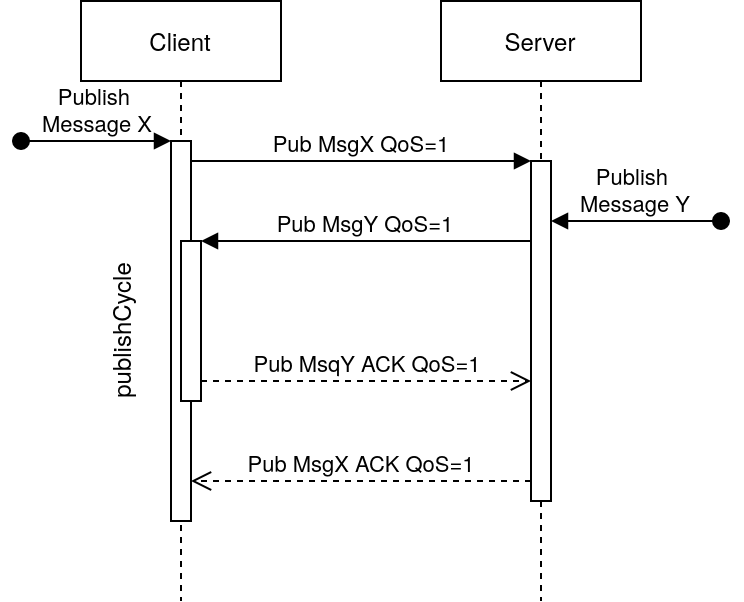
The customer wishes to publish a message X with quality of service (in this case, a simple acknowledgement). After sending the first packet, the broker also wants to publish a message Y (which requires an acknowledgement). For this to work, the client that sent the first packet would have to go back into its event loop, retrieve the packet from the broker, process it (i.e. send it an acknowledgement to indicate that it has received it), and then wait for the broker to send it the acknowledgement packet for its own X message.
In the eMQTT5 client architecture, when the event loop is launched, if a packet is received, the publication cycle (acknowledgements and/or registrations) is launched. This means that the client can call MessageReceived::messageReceived, which in turn may want to publish another packet.
We therefore have a recursion problem which could lead to the entire stack being used and the CPU task crashing.
Bearing in mind that the standard does not require the broker to respond immediately to a publication packet, it can also wait until it has received all its acknowledgements before sending its own. If there are 20 packets being sent to the client, this means 20 publication cycles to be completed before the first publication can be finished.
The broker might also react like this:
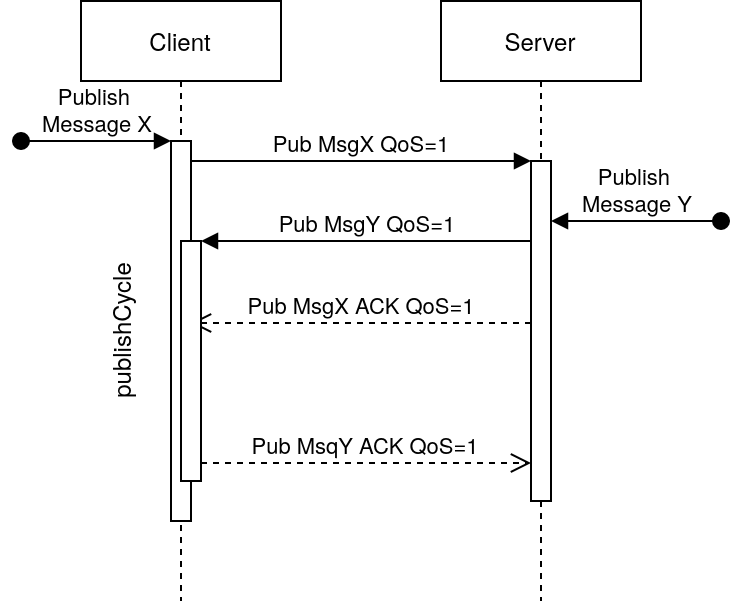
Here the response is sequential, i.e. the broker reacts immediately to the client's packet by sending an acknowledgement as soon as it has received message X (but after sending its own Y).
The eMQTT5 client can't/won't have to store pending messages (as this would mean allocating memory for them and fragmenting the heap).
The chosen solution is therefore to observe only the first packet received during a publication (with quality of service).
If the packet received does not correspond to the one expected (in the example above, an acknowledgement of message X), it returns a TranscientPacket.
In this case, it's up to the user to retry publication at a later date.
The user must call eventLoop again to process the incoming message (to purge the broker's sent queue) and retry publishing just after. It's not recommended to call eventLoop from within the messageReceived method since it creates a reentrancy issue that can lead to stack exhaustion/overflow.
Note that if the user does not publish during a message reception (in the messageReceived method), then the reentrance problem no longer arises.
To summarize:
- Always check the return of the
publishmethod call. - If it returns
TranscientPacketthen retry publishing, after callingeventLoopto purge pending messages. - If you absolutely must publish a message when a message is received (i.e. in the
messageReceivedmethod), then it is advisable to use a signal/variable that will be modified in this method, and checked in the code that calledeventLoopfor publication aftereventLoopreturns.